【原创研究】从GPU断供看中国AI自主可控之路
来源: 远桥资产-陈天伦日期:2022-09-02浏览量:488

在断供面前,资本市场和产业都有太多值得反思:当我们不得不直面赤裸的底层技术差距,究竟应该敲响中国AI产业和资本的警钟,还是用血的代价迎来国产GPU的狂欢?
8月31日晚间消息,美国开始对出口先进GPU施加新的限制,其中 AMD、英伟达(NVIDIA)等半导体巨头受到直接影响。自8月26日管制措施生效以来,NVIDIA和AMD的股价分别累计下跌15.8%和12.7%。

身处风暴中心的断供方:NVIDIA和AMD
AMD方面称总部已暂停对中国所有数据中心 GPU芯片MI100和MI200的发货;其中,MI100是已商用产品,而MI200将在2022年底商用,均采用7nm制程工艺,属于面向数据中心和先进计算的底层算力芯片。
根据英伟达的最新披露,“美国政府正式对A100 和即将推出的H100芯片向中国(包括香港)、俄罗斯的任何形式出口,均提出新的许可要求,并且立即生效”;这一管制措施将同样适用于英伟达未来推出的任何一款性能等于或高于A100的全新芯片。其中,A100芯片已商用,采用7nm制程工艺;H100在2022年3月推出,采用4nm制程工艺。
上述GPU芯片均属于具有双精度计算能力的高端先进算力,在国内销售主要面向:
1)国家超算中心,用于支持大规模尖端研究和先进计算;
2)Hyper-scale数据中心,如阿里、腾讯、百度、字节等互联网大厂;
3)人工智能企业,用于支持面向应用场景的大规模计算要求。
无论是直接面向数据中心的超算,还是面向AI应用的大规模智能计算,这一限制将直接导致先进算力的瓶颈。尤其在以计算机视觉为基础的庞大新兴领域,例如自动驾驶、实时渲染、AR/VR等场景,高端GPU进口缺失的影响可能是“致命”的:当我们不得不承受先进算力的“卡脖子”之痛,中国AI产业的落地成本将整体被迫抬升。受限于算力导致的这种畸变,高性能计算场景的瓶颈是显著的,甚至可能影响中国AI产业在相当长期内的竞争力。
以史为鉴,美国对中国先进计算的封锁在持续升级。这已不是美国的第一次“动手”:早在2015年,中国“天河二号”超算项目相关的4家中国机构被美国列入“实体清单”;而海光、中科曙光、飞腾等12家与先进计算相关的产业链上、下游企业先后在2019年和2021年进入“实体清单”。
新一轮出口管制表面看似唐突,实则却有迹可循。从划定“实体清单”到反向美国半导体巨头“面向所有中国区客户”的销售禁令,导致受影响范围从超算延伸至中国的人工智能和互联网产业;且单一技术点的断供,可能对AI产业的上、下游产生更加深远的牵连。
高端GPU断供,反映了美国对中国先进计算和人工智能产业的进一步封锁;而封锁背后,是中美两国在长趋势下不可调和的角力矛盾,以及最终科技竞争走向“半脱钩”的巨大隐患。
•7月30日,美国商务部禁止美国企业向中国提供14nm以下先进制程芯片的制造设备
•8月3日,佩洛西窜访台湾后会见台积电董事长刘德音,寻求以“芯片法案”围堵中国
•8月10日,拜登正式签署《芯片与科学法案》
•8月15日,美国商务部发布对EDA软件工具等四项技术实施出口管制
•8月26日,美国政府要求AMD、NVIDIA对中国区客户断供高端GPU芯片
美国“芯片法案”最直接的目的,无非是通过巨额投资补贴吸引半导体企业(尤其是晶圆制造企业)在美国本土建厂,实现半导体产业的回迁;同时,通过限制补贴资格来阻止半导体企业在中国增产,围堵先进制程芯片工艺落地中国,压制中国先进计算发展。显然,现阶段中国在14nm及以下的先进制程领域,仍然基本处于大面积空白状态;而即使是成熟制程芯片,核心制造设备、耗材的本土化供给程度也同样相当低。
结合“芯片法案”,GPU断供是美国变相要求半导体巨头“选边站”的实质性动作之一。作为中国的核心“卡脖子”技术,芯片产业俨然成为美国遏制中国崛起的最核心武器。从芯片设计、制造设备、晶圆制造等各个环节,美国正在并将持续全方位封锁和打压中国——因此,尽管各方对高端GPU断供的影响仍有争议,但不可否认的是长趋势下美国的技术封锁和打压将成为未来中美竞争的最重要主旋律:
如果断供的对象不是GPU,仍然可能是CPU、MCU……如果断供的不是数据中心侧的GPU,我们仍然面临端侧和消费级GPU的封锁隐患……如果断供的时间不是今天,仍然可能是明天,或者后天……
高端GPU的突发断供,引发市场对于国产GPU自主可控的关注。中国在关键芯片国产化和供应链安全所付出的努力是毋庸置疑的——国产GPU的自主可控,不单单仅是芯片安全,还涉及到中国AI产业的整体安全。
GPU(图形处理器)最初规模化应用于游戏显卡,而伴随着通用计算需求的演进,GPGPU(通用计算图形处理器)开始运行图形渲染之外的通用计算任务。基于并行处理能力强、计算能效比高、超大存储带宽等特性,GPGPU特别适合于某些应用场景,例如人工智能(机器学习)模型训练与推理、高性能计算等。
事实上,最初并不是GPU选择了人工智能,而是人工智能选择了GPU,进而成就了GPU:2012年Alex Krizhevsky(前谷歌计算机科学家)利用深度学习+GPU的方案,一举赢得Image Net LSVRC-2010 图像识别大赛,并奇迹般地将识别成功率从不足30%提升到85%。
换言之,GPU被赋予的意义早已不再是单纯的“游戏显卡”——作为人工智能皇冠上的明珠,GPU之于人工智能,就好比一砖一瓦之于屋舍楼厦。


GPU之于人工智能:先进计算的算力核心
通过分析过去五年具有代表性的芯片公司的股价走势,就可以对行业的发展趋势窥见一斑:英特尔近五年股价上涨了50%;Xilinx(全球领先的FPGA公司)股价大概上涨了2.6倍;而英伟达(当红的GPGPU垄断企业)过去五年股价上涨了超13倍。我们即便不去追究深层次的原因,仅凭股价的成长也可以判断行业已经作出了选择:GPGPU已经成为未来计算的主角和核心。
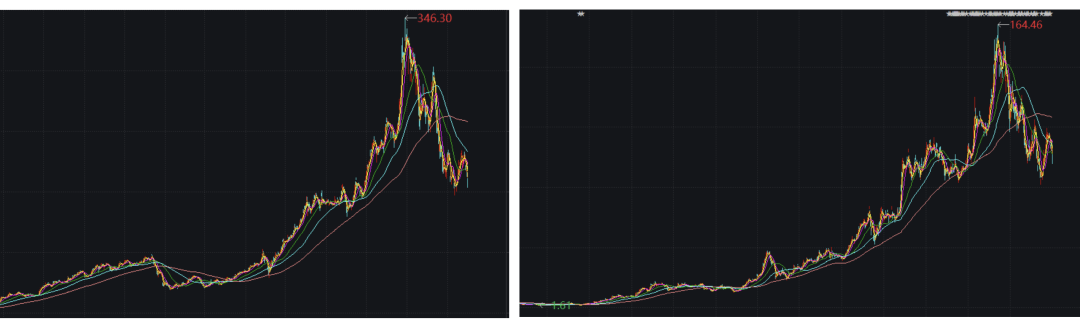
英伟达和AMD的股价图:成长于人工智能时代
作为人工智能的算力核心,GPU有着其自身高度的复杂性和特殊性,这决定了:国产GPU,不单单只是芯片产业的“卡脖子”技术,更关系到中国先进计算和人工智能产业的自主可控。因此,当我们在谈国产GPU的自主可控时,不只是保障“中国芯”安全,更是保障架设在GPU之上的人工智能计算与应用安全。
“给我100亿,我要造出替代英伟达的国产GPU!”
这样的口号也许在几年前是“天方夜谭”,但现实是,供应链安全的大刀正在关闸——国产GPU攻坚正在艰难地成为事实。近两年,国产初创GPU公司累计拿下了超百亿的融资:成立18个月的壁仞科技融资总额超过50亿;摩尔线程一年融资超30亿;沐曦第五轮单轮融资超10亿元…举国之力“造芯”,从神话走向现实。
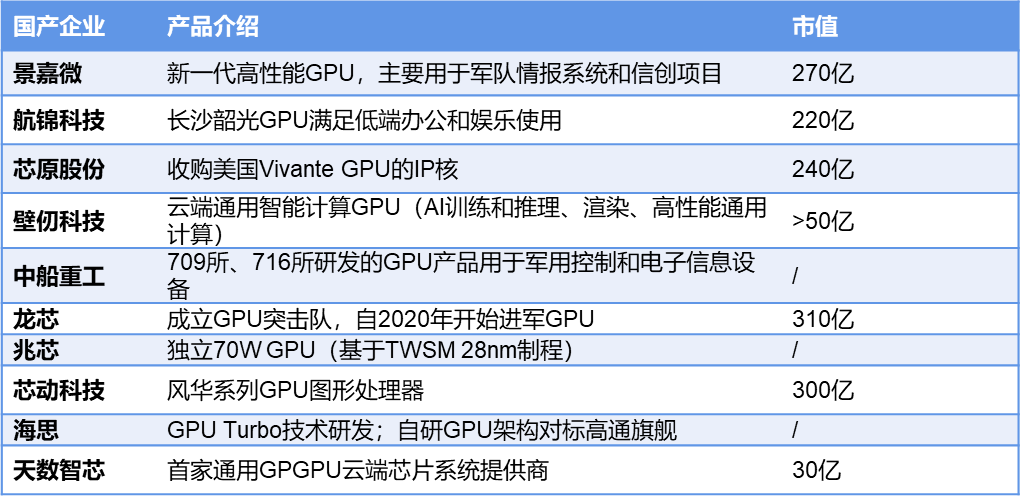
“给了你100亿,你真的能造出替代英伟达的国产GPU吗?”
心酸的是,这个问题我们仍然无法回答;至少在现在,我们必须承认底层的技术代差仍然不可小觑;在高端GPU领域,国内仍然是空白状态。根据现有国产GPU厂商提供的“纸面数据”,领跑者(如壁仞)已经可以和英伟达2016-2017年的系列相比肩,技术代差缩短至5年左右。但同时,应用调试、软件适配方面的差距,也不可能是一朝一夕可以完成的。
市场需要的不是“好”的芯片,而是“好用”的芯片。这也是国产GPU最大的瓶颈之一。所谓好的芯片就是绝对算力高、硬件指标高,这个相对容易做到。但是做到好用就很困难。以史为鉴,英伟达其实也是一步一步从不好用做到好用,走过了一个漫长的阶段。早期的GPU是很不好用的,没有什么人会用GPU编程,只有那些所谓的“极客”会考虑使用GPU——早期的GPU比现在的AI芯片更不好用。
英伟达的真正高明之处,是在芯片的基础上衍生了CUDA生态体系。因此,NVIDIA经常标榜自己是个“软件公司”:CUDA使开发者拥有了直接对GPU进行编程的语言,使得GPU的潜力得以充分发挥,从而真正走上了腾飞之路。又经过十年左右的发展,形成了一个非常强大的生态,可以支持各种各样的应用,丰富了高级语言的属性,能够支持更为复杂的模型和算法,并且逐步在很多行业形成垄断。
国产GPU的自主可控之路,还要“打很多怪,升很多级”。在这个高度垄断的行业,全球GPU技术领域专利数量排名前20的公司占有全球70%的GPU专利;而国产GPU与英伟达的技术代差仍然存在着巨大的鸿沟。同时,由于缺乏CUDA生态,国产GPU公司很难把一块“好的芯片”变成“好用的芯片”。
在断供面前,资本市场和产业都有太多值得反思:当我们不得不直面赤裸的底层技术差距,究竟应该敲响中国AI产业和资本的警钟,还是用血的代价迎来国产GPU的狂欢?
短期内看,供应链压力非常突出。考虑到A100、H100 在各大渠道商和OEM厂商的库存和呆滞物料,下游影响应该相当有限,但上游供应链会有很大压力。需求方在不确定性恐慌下会大面积囤积算力,供应商甚至借机囤积居奇——算力成本的抬升是无疑的。
中长期来看,是国产芯片的重大利好。之前有政策扶持,现在市场机会也来了。尤其是做 AI 训练芯片的初创公司,如:海思、昆仑、壁仞、燧原。之前有 30% 的性能提升可能都不会考虑(生态不行),现在有 30% 的性能差距可能都不是问题了(刀架脖子上了,先用起来再说,至于软件生态,慢慢补吧)。而市场对于英伟达的信心,正在逐渐发生政治性动摇:任何公司会越来越倾向于储备Plan B ——Plan A 虽好,可谁知道哪天又断供了。
相较于全球范围内的人工智能产业发展,中国有着极其良好的产业土壤。丰富的应用场景、庞大的数据训练量、相对廉价和充裕的“工程师红利”是中国特有的长板。这决定了我们在AI算法的研发、应用和投入产出比上有着先天优势。
然而,受制于先进算力的进口限制,我们算法的成本优势不足以覆盖新增的算力支出。可见的是,中国AI产业的落地成本将整体被迫抬升。受限于算力导致的这种畸变,高性能计算场景的瓶颈是显著的,这可能影响中国AI产业在相当长期内的竞争力。
高端GPU断供,敲响的不仅是芯片之警钟,更是中国先进计算和人工智能产业之警钟。打造国产GPU自主可控,是中国AI产业保持竞争力和持续落地所必须奠定的根基所在。
国产GPU:自主可控决心不可低估,开启长期景气周期外有3D视觉、人工智能时代对于GPU的呼唤,内有供应链安全、芯片国产化的必然要求,国产GPU先天享受着供给侧和需求侧的双重红利。本次高端GPU断供事件,进一步敲响了中国先进算力缺陷的警钟,在相当长的时间内开启国产GPU的景气周期。
影响最为直接的,是我们能看到资本的持续涌入和青睐。但热闹之余,我们仍然要直面国产GPU和英伟达之间的技术代差、生态代差、应用代差。经过长周期培育,国产GPU亟待从一块“好的芯片”变成“好用的芯片”,才会有从信创走向消费级市场的可能。
ICT产业投资:从单纯的商业模式创新向基础设施攻坚倾斜在过去的5年里,中国的AI产业收获了全球规模最大的VC投资。我们正在推动人工智能对于不同行业、不同场景的应用和转化,重塑传统产业和居民生活的规则和逻辑。可见的结果是,中国在人工智能的应用上领跑全球,这不仅得益于中国良好的产业土壤,也和资本持续的涌入和青睐密切相关;但显然,我们短暂地忽视了人工智能的基础设施,甚至选择性遗忘了我们仍然存在基础设施“短板”。
高端GPU断供,残酷地启示我们:如果“短板太短”,我们的“长板再长”都将没有意义。伴随着海量数据和应用场景的训练优化,人工智能算法在长周期内的门槛正在降低;对于人工智能产业发展而言,算力的自主可控将是关键的一步。同理,依赖于商业模式创新或单一算法应用的投资,其边际价值正在下降;我们理应将目光转向不同应用场景的底层算力。中国AI产业投资之余热,必要也应该从单一的商业模式创新向基础设施攻坚所倾斜,从单一的应用场景向底层硬实力所倾斜。