【原创研究】AI 2.0时代,寻找卖水人
来源: 合伙人 王韬日期:2023-06-10浏览量:264

作者 | 合伙人 王韬
“人工智能革命重要程度不亚于手机和互联网的诞生, OpenAI 的 GPT 模型,称其是自 1980 年现代图形用户界面以来,最具革命性的技术进步,AI时代已经开启。”微软的创始人比尔盖茨评价。一项技术的影响和生命力,一定是从它对全人类社会带来的效率提升开始的。大语言模型引领下的本轮AI2.0的浪潮之所以被赋予了如此之高的期待,原因也是在于其带来社会生产效率层面的指数级提升。3月20日,OpenAI发布论文:“大语言模型将对劳动力市场造成深远的影响。语言大模型对劳动力市场的潜在影响对于约80%的美国人来说,他们至少10%的工作任务会受到大模型的影响;此外有约19%的人,其工作任务受影响的比例超过50%。”

在美国,大模型发布以来,各个行业基于大语言模型的效率工具,几乎是一夜之间如雨后春笋冒出来,赋能于各个领域的效率提升。在国内虽然大语言模型的起步比美国更晚一点,但是在模型应用的探索速度上追赶很快。4月12日,蓝色光标全面裁剪文案外包人员,打响本轮AI大规模替人第一枪,公司内部的邮件表述:“为了遏制核心能力空心化的势头,也为了给全面拥抱AIGC打下基础,管理层决定无期限全面停止创意设计、方案撰写、文案撰写、短期雇员四类相关外包支出。”我们同行的众多ICT产业龙头,在评估大模型带来的影响后,也得出了相似的结论:AI大模型虽然还处在产品化的探索阶段,但是仅在公司内部使用,就已经带来了大幅的效率提升。部分公司反馈,同等产出的情况下,可以优化20-30%的中低端程序员,30%-40%HR,财务等事务性岗位,给公司整体经营成本带来15-20%缩减并最终反映在净利润率水平上。
AI2.0展现出显著特点是“机器智力的提升”,对人类多元化的工作进行显著的增效和替代。虽然当下,模型算法成熟度还比较低,实现成本和应用门槛都也比较高,但已经带来了非常惊人的效率提升。这使我们对AI 2.0时代的周期和高度有很大的期待。我们坚信接下来的几年,AI2.0逐步地渗透和蔓延,机器会逐步取代大量的人工,成为社会生产过程中的主要劳动力。在这个浪潮之下,政府,企业,每个个体的竞争维度很快会从自身的效率比拼转而变为,谁能更快更好地拥抱AI,运用AI,AI产业也会迎来前所未有的巨大发展。
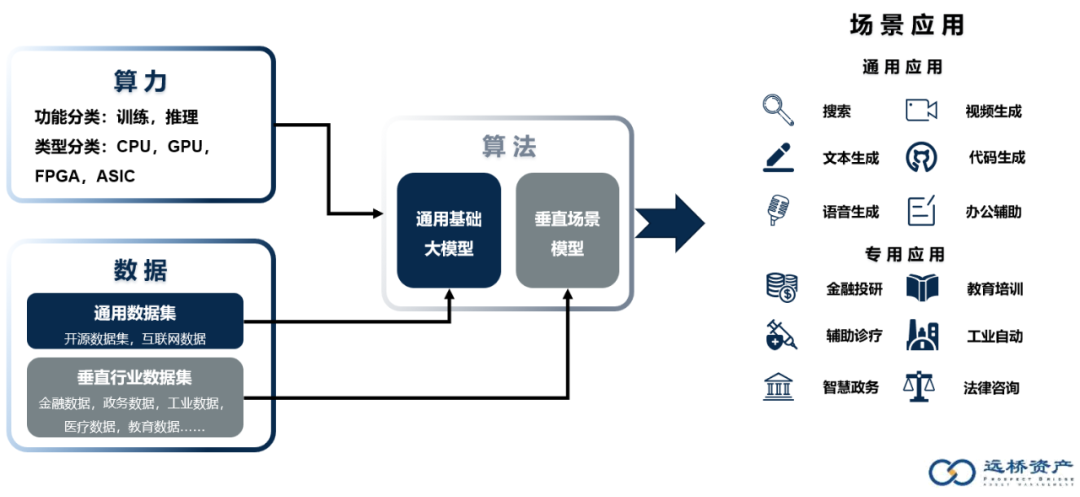
从产业链角度看,构成AI落地的上游核心的要素,包括了算力,数据和算法,与AI 1.0时代相比,三者的内在需求和逻辑都发生了较大的改变。基于算力,算法,数据,落地成为行业的产品或解决方案,最终服务于下游的通用或专用的场景。
虽然当下,产业界,投资界,媒体都在开始火热地畅想AI2.0带来的巨大改变,但如果我们去借鉴过去互联网,智能手机等重大科技趋势的规律时,会发现:一个可能延续十年以上的科技改变,会遵循着从“基础设施建设——配套逐步齐全——成本下降——应用百花争鸣”的产业演化过程。因此,站在今天,我们应该清楚的意识到,应用场景的探索和落地虽然非常有想象力,但是上游算力,算法,数据这些卖水赛道,才是AI2.0的基础,也是我们站在今天率先应该去布局和投资的领域。◆ “兵马未动,粮草先行”——国产AI算力芯片爆发确定当前大语言模型引领的AI2.0浪潮,已经形成了产业端的共识和持续投入,但基础设施的建设目前还相对昂贵,动辄数百万,千万甚至上亿美元的基础模型研发投入,这些研发投入,最终都需要场景和应用来付费买单,此刻大家去拿着锤子去找钉子时,会发现应用端可以敲的钉子不够多,此刻在应用端投资相对胜率会比较低。现阶段我们更看到的更大的机会,更有效率的投资是寻找AI趋势落地的过程中卖水的企业,这与互联网早期,最早一骑绝尘的思科,是同样的道理。二级市场已经投票,ChatGPT发布至今6个月的时间,英伟达股票上涨146%,寒武纪股票上涨了251%,市场对于未来的高算力模糊但确信的展望。以GPT-3中1750亿参数的模型的训练为例,需要3.14 * 10^23次浮点运算(FLOPs),假设想要在10天内完成这一模型的训练,会需要10830万英伟达A100芯片搭建的集群,而购买这些A100芯片搭建集群的成本在1-2亿美金。这就是市场流传的“没有一万张A100,数亿美金的储备,不敢说自己要去做大模型”。在实际执行的过程中,通常拉长训练时间,降低模型参数,租赁云端算力等方式来向现实和钱包妥协。即便如此,算力成本依旧占到了AI大模型产品落地总成本中的70-80%。站在市场需求角度,我们在与英伟达以及大量紧跟AI的ICT龙头开展交流和调研后认为,在中国AI对算力的需求增长会经历有3个阶段:大模型展现出了强大的降本增效的能力,产业方考虑的是落地到场景中实际的效果会如何,投资多久可以收回成本。本轮AI浪潮在未来1-2年内,会率先迈入模型验证期,市场广泛产业方,创业企业,科研单位,大厂,会结合自身的业务和场景,先后对AI落地的有效性进行验证,寻求一个答案:“我应该以什么样的力度去拥抱大模型?”参考英伟达的预测,这种广泛和分散的验证需求,未来2年预期新增每年百亿规模的GPU市场规模。根据交流,许多走在前列的科技公司与巨头实际已完成场景有效性的初步验证,转而进入模型迭代期,模型的大小即意味着算力和成本,但却不一定代表有效性,因此总多产业方选择的方式是,逐步结合场景,数据和商业化的进程,采用小步快跑的方式逐步从6B-15B-60B-千亿向上增加模型参数规模。这一阶段预期会在未来3-5年在各个行业发生,考虑到模型的敏捷迭代,市场会新增数倍于验证期的通用AI算力需求。伴随着模型的逐步成熟和场景商业化的推进,AI大模型的能力逐步推广和渗透是后续的必然。就像当下互联网,物联网的蔓延和渗透一样,AI的能力在成熟后也会逐步渗透到各个端侧,预期未来5-10年,端侧对AI的推理应用的需求将会迎来爆发,届时AI通用泛化的能力会进入到我们手机,电脑,ARVR设备,甚至工厂的机器,头顶的摄像头,物理世界中的各个角落,进一步推动我们场景的智能化。届时,更固化但更具成本和性能优势的定制芯片(ASIC等)逐步走上算力的舞台,成为训练和推理的强有力选择。面对算力需求端的成长机会,市场的供给又在何方?依托芯片技术的长期积累,十余年长期经营的Cuda生态,面向AI训练专门设计的Nvlink等绝对的领先优势,截至目前,英伟达在中国AI运算算力市场占据了85%以上的市场份额,是AI大模型时代的最大赢家。但中美对抗的宏观环境下,英伟达被限制出售中国A100及以上产品,只能供应A800阉割产品。算力层面的限制,客观上较大程度制约国内模型算法的创新和应用领域的开拓。对于中国未来逐步爆发的AI大模型市场,是比较明确的供应链安全问题。因此,在AI 2.0的浪潮下,我们优先看好中国算力的机会,作为卖水赛道,无论是市场空间的分阶段增长,供应链安全下的国产比例提升,国内的AI算力公司都有很大的机会,同时,在前期模型的敏捷迭代和开发生态非常重要,我们更看好通用AI算力(GPU/GPGPU)的企业。

数据方面,伴随着OpenAI对大模型实验过程的逐步揭秘,所有人都开始意识到高质量,丰富性,大规模的数据集是ChatGPT取得成功的重要要素:高质量数据集能够提高模型精度与可解释性,减少训练时长;增加训练数据量、模型参数规模或者延长模型训练时间,预训练模型的效果会越来越好;数据丰富性能够提高模型泛化能力,扩充AI的应用场景。
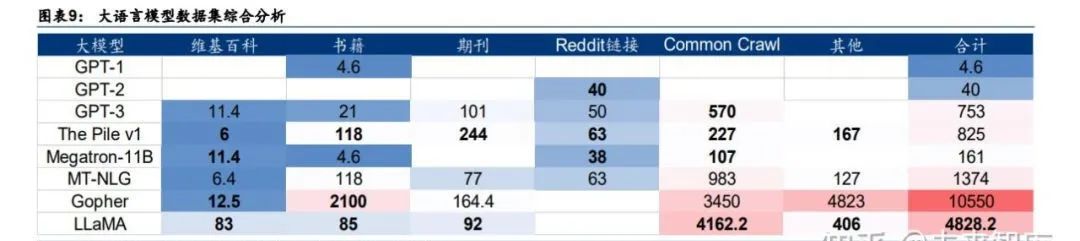
2018年后,AI大语言模型训练使用的数据集规模持续增长。2018年的GPT-1数据集约 4.6GB,2020年的GPT-3数据集达到了753GB,到了 2021 年的 Gopher,数据集规模已经达到了10550GB。

成功的经验使得技术跟进方,采用了相似的方式去复刻AI大模型的训练过程。但实际训练的过程中,对于“高质量”,“大规模”“丰富性”的度是很难把握的,也并没有数据和模型效果准确的线性关系指引,需要在模型迭代的过程中一点点去调整。
落地到数据环节,又会有怎么样的卖水的机会?
我们看到的重要趋势是,互联网大厂正在不断扩充大模型的数据集,基于互联网的,公开可获取,其他渠道可链接的数据和知识,都在不断纳入其中,在基础大模型的迭代和泛化过程中,逐步成为基础大模型的公共能力。
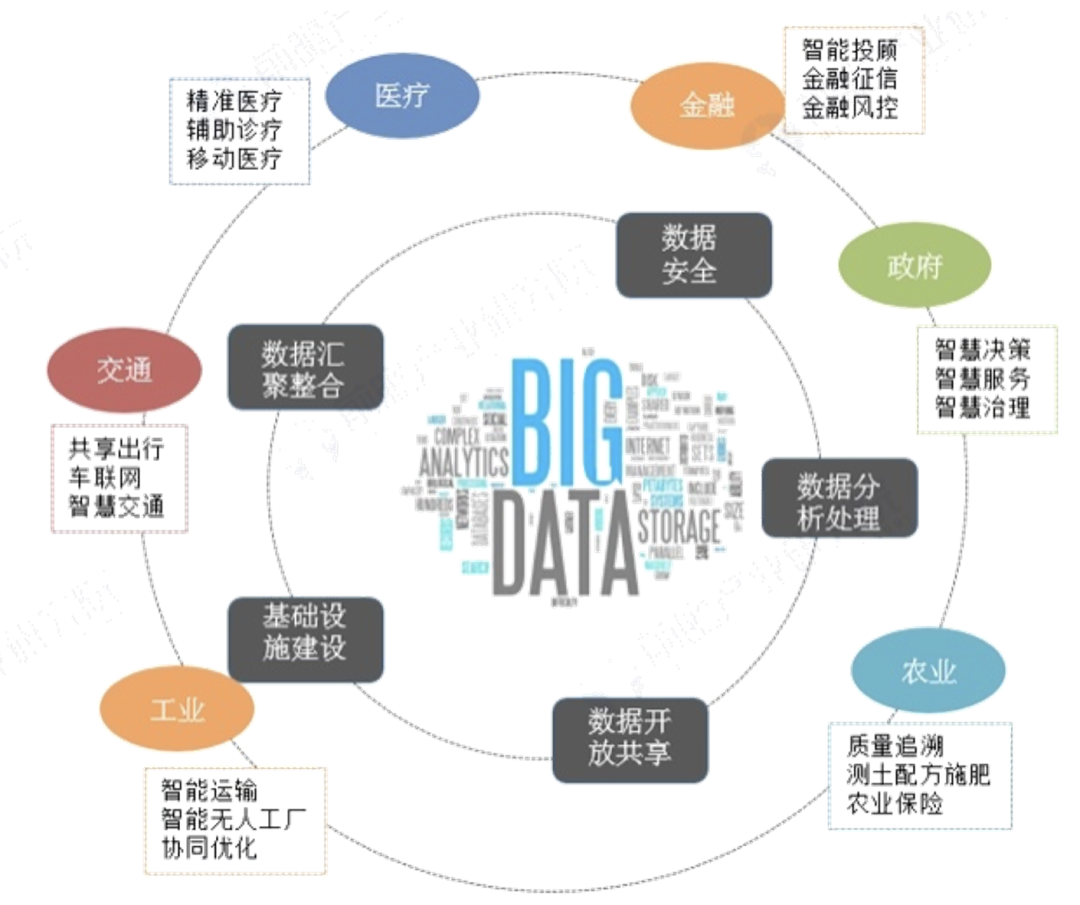
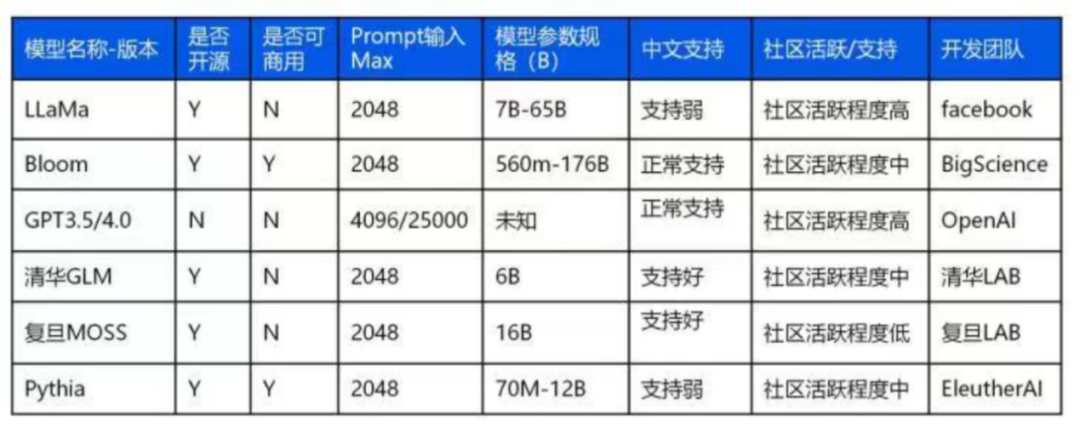
但互联网数据并非囊括了全部行业的知识数据,许许多多传统行业,互联网化和云化正在进程前期阶段,大量的数据和知识仍处在散落状态,未被结构化。这几年,大数据产业的发展,数字中国政策的落实,持续在推动各个行业的数字化,数据结构化,行业知识图谱的积累。我们认为基础大模型的能力边界会限于当前公开数据集可覆盖的领域,进而构成AI2.0的基础能力。但是围绕金融,政府,工业,医疗,教育等众多封闭垂直的传统行业,仍存在众多碎片化的数据和知识,这些数据和知识同样非常有价值,会逐步构成垂直大模型的基础,在这些领域深耕的数据采集,流通,交易服务商,将会是AI 2.0浪潮下值得关注的卖水人。在算法层面,跟进海外近6个月基础大模型的迭代和商业发展,我们认为创业公司非常难在基础大模型层面取得胜出。基础大模型迭代和完善,是一个持续性实验投入的过程,即便是在OpenAI已经披荆斩棘走出一条可行的道路,我们看到后发跟进者,哪怕是谷歌,追赶仍然不是一个容易的事情。采用完全相同的数据集,充足的算力,复现的实验过程还一些玄学的部分,需要一点点调整和优化。对于创业团队和投资人,如何在面临持续融资压力,商业化压力等诸多困难环境下,去保持对不可控实验结果的巨量持续投入,这在我们看来是一个伪命题。Meta在大语言模型的技术跟进上虽然进展缓慢,模型效果也不佳,但误打误撞泄密/开源了LLaMa,反而成就了当下最活跃的大模型开源社区,围绕LLaMa的论文,衍生的模型,以及在此模型上的优化和提升手段都在持续涌现,Meta成为了最大的受益者。因此我们认为,基础通用AI大模型未来发展路径很明确,一定是科技巨头/大厂与开源社区共同演进的结果。追赶者为了抹平技术差距,会无负担地推动开源的演进,留给创业企业通过技术换空间,构建商业模式的机会很小。
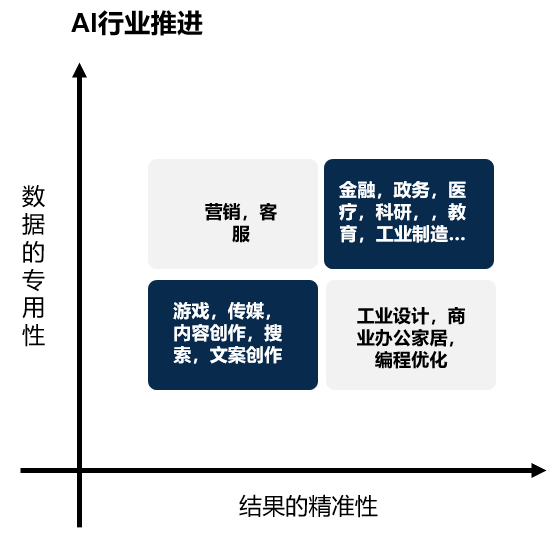
上图来自中欧国际工商学院杨蔚教授的研究,从AI2.0的行业扩散顺序上看,我们看到率先在游戏,传媒,内容创作,文案书写,搜索等领域率,AI实现应用落地和人力替代。这些领域,知识和数据集被很好地做了结构化并在互联网上充分可获得,同时在场景落地时,对于AI输出结果准确性要求较低。AI基础大模型的通用和泛化能力很快满足了应用的需求。举个例子,“文案创作”这种弱准确度就能商业化的赛道,基于在互联网上积累了足够多文案内容,并可以通过公开手段或爬取的方式获得,那么很快,百度文心,阿里通义,京东犀言……各个通用大模型会很快覆盖一定水平的文案创作能力,对赛道内创业企业形成冲击与替代。在垂直行业专用数据领域,数据集天然存在碎片化,采集,结构化,构建,本事是一种门槛并且需要花费时间;更多的场景对于AI生产的内容,是由更高准确度的要求,这也意味着AI2.0还需要结合场景持续迭代至达到相应的要求才能落地应用。因此,我们对AI2.0在各个场景中的蔓延和渗透做出了如上的预测判断。但相应来说,这些要求反而成为了行业的壁垒,使得通用大模型很难快速泛化到上述的领域,也代表着这些垂直领域赛道的算法工具类企业,有机会通过一定的技术领先优势,转换成时间与空间,进而落地出商业模型和规模化的收入。
3,结语
AI 2.0的浪潮方启动,这是一个长周期内持续带来效率提升的科技趋势,我们可以预见,运用AI的能力会逐步成为政府,企业,个人的核心竞争力。但是,就如同站在智能手机浪潮的初期,没人预知华为会后发制胜;移动互联网浪潮初期,赢家字节跳动尚未入局。作为投资,我们应顺势而为,把握AI爆发的早期确定性机会,寻找和投资于AI“卖水人”,拥抱AI,把握未来。